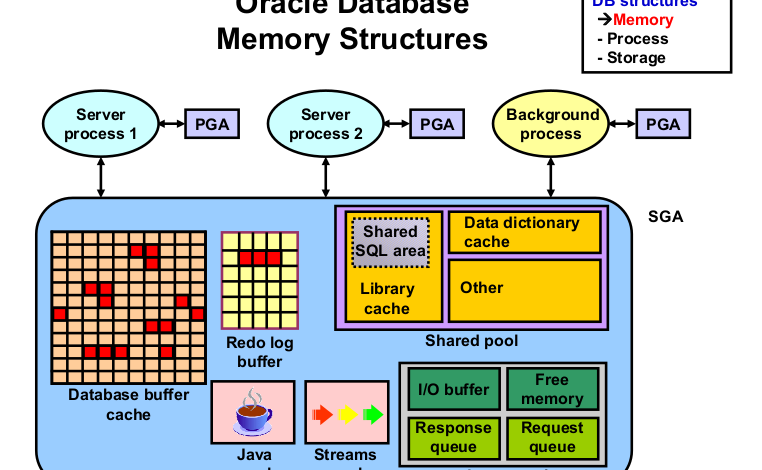
Oracle database utilizes various memory structures to efficiently manage and store data. These memory structures play a crucial role in enhancing performance and ensuring data integrity.
Here’s an introduction to the main memory structures in Oracle:
System Global Area (SGA):
- The System Global Area (SGA) is a shared memory region that stores data and control information for an Oracle database instance.
- It includes various subcomponents such as the buffer cache, shared pool, redo log buffer, large pool, and Java pool.
-
The SGA share among all connected users and processes, allowing efficient access to user data.
Buffer Cache:
- The buffer cache is a portion of the SGA that caches data blocks retrieved from disk.
- It holds frequently accessed data blocks to reduce disk I/O and improve performance by providing faster access to data.
-
The buffer cache’s managed by the database’s cache manager, which determines which blocks to load, evict, or keep in the cache.
Shared Pool:
- The shared pool is another component of the SGA that contains shared memory structures, including shared SQL and PL/SQL areas, data dictionary cache, and shared cursors.
- It stores parsed SQL statements, execution plans, and frequently used data dictionary information to improve performance by eliminating the need for repeated parsing.
Redo Log Buffer:
-
The redo log buffer is a part of the SGA used to hold changes made to the database before being rewritten to the redo log files.
- It captures a record of all modifications made to the database, ensuring recoverability and providing a mechanism for database recovery.
Program Global Area (PGA):
-
The Program Global Area (PGA) is a memory region divided for each individual Oracle database session or process.
- It stores session-specific data, such as private SQL areas, stack space, and session variables.
-
Each dedicated server process or background process has its own PGA, which is not shared among many sessions.
Large Pool:
- The large pool is an optional component of the SGA that provides additional memory for large allocations and specific operations.
-
It’s used for various purposes, including backup and recovery operations, parallel query processing, and shared server connections.
Java Pool:
- The Java pool is an optional component of the SGA that stores Java-related data and code used by Oracle’s Java Virtual Machine (JVM).
- It caches Java classes, methods, and other Java-related structures to improve the performance of Java-based database applications.
Managing and tuning these memory structures is crucial to optimize the performance of an Oracle database. The allocation, configuration, and tuning of these memory structures handle through Oracle initialization parameters and dynamic memory management features provided by the database system.
Database Memory Structure
The memory structure of a database refers to the way data organize and stored within the database system. There are different memory structures used in databases, and the choice of the structure depends on various factors such as the type of database, performance requirements, and scalability needs.
Here are some used memory structures in databases:
1. Heap File Structure:
In a heap file structure, record store in no particular order. Each record’s appended to the end of the file as it inserts. This structure is simple and efficient for appending records, but it can lead to slower retrieval times as there is no specific order in which the record’s store.
2. Sorted File Structure:
In a sorted file structure, the record store in a particular order based on the values of one or more fields. This allows for faster searching and retrieval operations, especially when using binary search algorithms. However, maintaining the sorted order can be costly when inserting or deleting records.
3. Hashing:
Hashing involves mapping key values to specific locations in memory using a hash function. This structure is often used for quick retrieval of individual records based on a unique key. Hashing provides constant-time access to records, but it may suffer from collisions (two different keys hashing to the same location) that need to resolve.
4. B-Tree:
B-Tree (Balanced Tree) is a user data structure for indexing in databases. It organizes data in a hierarchical structure, where each node contains multiple keys and pointers to child nodes. B-Trees’s balanced, meaning the height of the tree keep low, ensuring efficient search and retrieval operations even with a large number of records.
5. Indexes:
Indexes are separate data structures that create to improve the performance of database queries. They can install using various techniques such as B-Trees, hash tables, or bitmap indexes. Indexes provide quick access to data based on specific columns or attributes, reducing the need to scan the entire database.
6. Caches:
In addition to the main storage structures, databases often use caches to improve performance. Caches are smaller, faster memory areas that store frequently accessed data or query results. By keeping frequently used data in memory, databases can reduce disk I/O and speed up query execution.
It’s important to note that the memory structure within a database system manages the database management system (DBMS) and is not visible or accessible to the end user. The DBMS abstracts memory management and provides high-level interfaces for data access and manipulation